High-dynamic range (HDR) imaging is way of dealing with the fact that digital cameras can record image intensity data much more accurately than computer monitors and printers can reproduce them. In fact, non-photorealistic HDR even makes up for the fact that digital cameras can record intensity information even more reliably than we can view it.
At the heart of HDR is the tonemapping process that compresses a huge (16 bits or more) intensity space into a small (8 bit) intensity space. Several tonemapping algorithms have been proposed and give different kinds of results. However, most existing implementations of these algorithms are not real-time. You select some parameters, hit the tonemap button and wait seconds, minutes, or hours, for the result. After which you may need to adjust the parameters and start again.
The goal of this project is to take one or more tonemapping algorithms and implement them as a library (with prototype application) that is suitable for real-time previewing and very fast output. The techniques used for this will probably include multiresolution image processing.
Real-time Decompression Algorithms
When recreational and comercial divers are at depth, they are exposed
to compressed breathing gas mixtures. During this exposure, the inert
gases in these mixtures (usually nitrogen and/or helium) are absorbed
into the divers tissues. These divers make careful and slow ascents
that include decompression stops
so that these dissolved gases
are slowly released from their tissues
and expelled through the lungs. Ascending too quickly can lead to
a condition dubbed the bends
in which bubbles form in the
divers tissues and/or bloodstream that can
cause fatigue, pain, damage to the central nervous system, and even
death.
There are many pieces of desktop software used to plan dives and provide decompression schedules to avoid the bends. Many divers also carry a dive computer with an electronic depth gauge that models, in real time, the amount of dissolved gases in their tissues and gives a real-time decompression schedule. Unfortunately, all these computers either use proprietary decompression models or use a closed source implementation of a published decompression model. Often, comparing different computers that claim to implement the same decompression model will expose large variations in the resulting decompression schedules.
Given the possible consequences (including pain, permanent injury, paralysis, and even death) of bugs in the implementations of decompression algorithms the current situation is unacceptable. The goal of this project is to provide Open Source implementations of some of the more popular decompression models that are suitable for use on a dive computer. This means the implementations must handle real-time data, work with limited processing power and, above all, be correct and bug-free.
- Information about the VPM decompression model
- Freeplanner (decompression software with available source code)
Faster and More Flexible Searching in the HTML DOM
The HTML DOM describes how an (X)HTML/XML document can be represented
as a tree and gives a mapping of the parts of this tree to objects.
The implementation of the HTML DOM in JavaScript is what makes dynamic
web pages possible. One of the most common operations in the HTML DOM
is to find all elements in the document with a given ID, Name, or Tag
Name (document.getElementById(),
document.getElementsByName(),
document.getElementsByTagName()).
Spend a bit of time experimenting with this script and you will soon find that these methods work by traversing the entire tree to find the node(s) being searched for. There are much more efficient ways of doing this (hashtables come to mind), and JavaScript is such a flexible language that you can easily modify the DOM implementation to use these instead.
This project would involve designing and implementing an efficient data structure that is integrated with the JavaScript DOM implementation that allows these operations to be executed efficiently. This project requires, at the very least, an advanced knowledge of data structure design techniques and strong programming ability.
Experimental Algorithmics
My research area is in the design of efficient algorithms for a variety of computational problems. Like most of my colleagues I design algorithms, prove their correctness, and prove bounds on their running times but I seldom implement them. I am, however, interested in robust and efficient implementations of algorithms, especially geometric algorithms, especially my own. Implementing and experimentally evaluating an algorithm for the first time is a good opportunity to really learn the intricacies of the algorithm, to find any technical difficulties in implementing it, and to find any optimizations that might make it work better in practice.A project in this category requires the robust implementation of one or more algorithms (subject to my approval) and a thorough battery of performance and correctness tests. If you are interested in implementing an algorithm or two, have a look at my list of publications and see if there's something there that interests you.
A C++ Library for Cache-Oblivious Algorithms
Cache-oblivious algorithms are algorithms that work in external memory (on disk, say) without knowing any of the parameters of the external memory (block size, say). Many algorithms and data structures for the cache-oblivious model have been proposed, but very little effort has been made to experimentally compare these algorithms with each other, or with cache-aware algorithms.
The goal of this project is to design a little C++ library for the implementation of cache-oblivious algorithms. The main part of this library would be an array implementation that transparently reads and writes parts of itself to disk when necessary, so that it only ever occupies a small part of internal memory. The library would be tested and tweaked by implementing several cache-oblivious algorithms and data structures using this array abstraction.
A Less Intrusive Profiler
A profiler is a system that monitors a program to see how long the that program spends in each of its subroutines. Profilers are used for finding frequently executed sections of code (hot spots) so that they can be optimized. Profilers work either by stopping the program at some random times and recording the current instruction pointer (subroutine) or by inserting code into the program so that each invocation of a subroutine is recorded. In both cases, all this data is stored somewhere and post-processed to come up with the program's "profile."
The problem with this approach is that profilers require some place to store all this data. This means that the machine the program is running on must either have a lot of memory or a hard disk. This makes profiling embedded software very difficult. It also means that profiling a program may change its behaviour since the program being profiled has less available memory or is frequently halted while the profiler writes data to disk.
For this project I would like to treat a profiler as a program that processes a data stream consisting of the subroutines (or even individual lines of code) that are executed. Recently, many researchers have proposed algorithms for finding frequently occuring items in data streams and these algorithms require only a small amount of memory that is independent of the length of the data stream. As an example, it is possible to find all items in a data stream that occur more than 10% of the time by using only 10 counters and labels. Using these algorithms we could develop a profiler that does not require much (internal or external) memory or time.
P. Bose, E. Kranakis, P. Morin, and Y. Tang.Bounds for frequency estimation of packet streams.
In Proceedings of the 10th International Colloquium on Structural Information and Communication Complexity (SIROCCO 2003), 2003.
[pdf] [ps.gz].
Finding Corners in 3-D Scanner Data
3-dimensional scanners (laser range finders and coordinate measuring machines) can measure an object by taking a sample of points on its surface. These points are usually then fed into some reconstruction software that attempts reconstructs the surface of the object from this point data.
For the most part, this software works well, particularly when the object is smooth (like a ball). However, where these algorithms tend to break down is in maintaining sharp corners. For example, the two images below show a perfect cube and a reconstruction of a cube from a sample of 6000 points on the surface of a perfect cube. Notice that in the second image, the corners are not quite as sharp.
 |
 |
The goal of this project is to develop efficient and accurate algorithms to detect corners in 3d-point data and perform reconstructions that preserve these corners. Efficiency is as important as accuracy here because the resolution of 3d scanners is becoming such that the number of sample points is huge.
2-Dimensional Depth Algorithms
Data depth is a field of statistics where one tries to assign, for
each point in Rd a
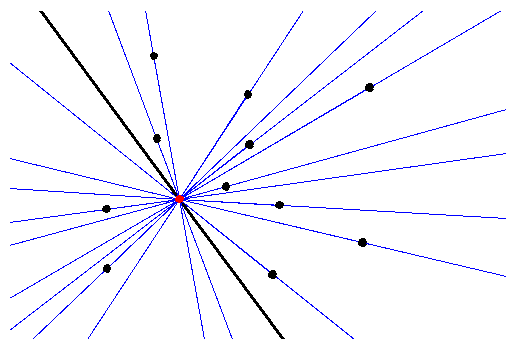
Once a depth function is defined then a number of computational questions arise:
- How do we compute the depth of a point p in a set S?
- How do we find the point p* of maximum depth?
- How can we compute the contour of all points whose depth is bigger than some value?
There are many definitions of depth for which the answers to these three questions are not yet known. In other cases, efficient algorithms have been proposed, but there are still no implementations of these algorithms.
The goal of this project is to develop efficient algorithms for solving depth problems in 2 dimensions and to implement these algorithms in a data depth library.
Prefix Trees with Constant Structural Change per Update
A prefix tree is a binary search tree in which each node stores the
size the of the subtree rooted at that node. Using any of the usual
balancing schemes, prefix trees support the
usual binary search tree operations of Insert and
Delete, and Search in O(log
n) time each. In addition, they also support the operation
At(i) that finds the element with rank i in
the same time bound.
Many search tree implementations such as red-black trees, and 2-4
trees have the nice property that updates only perform a constant
number of changes to pointers in the data structure. Unfortunately,
prefix trees don't have this nice property since each insertion
requires incrementing the sizes of the subtrees on a root-to-leaf
path. Is it possible to support the prefix tree operations of
Insert, Delete, Search, and
At with a data structure that only performs a constant
(amortized) number of pointer changes per update operation?
Finding such a data structure could shave a logarithmic factor from the space complexity of the range-median data structure described in the following paper:
D. Krizanc, P. Morin, and M. Smid.Range mode and range median queries on lists and trees.
In Proceedings of the Fourteenth Annual International Symposium on Algorithms and Computation (ISAAC 2003), 2003.
[pdf] [ps.gz] [full pdf] [full ps.gz].