The floating buffer tree was designed to take advantage of the buffer tree concept to improve the efficiency in answering online queries. The general idea is that we can achieve optimal I/O efficiency if any R-Tree node is loaded into main memory just a single time to answer all K queries. Furthermore any node not needed to answer one of the K queries will never be loaded while the batch of queries is being processed.
To achieve this rather than fix buffers to nodes at certain levels of the tree buffers are allowed to 'float' and are attached to, and removed from, nodes on a as required basis. The algorithm works basically as follows. All queries in a particular batch are initially added to a buffer attached to the root node. This buffer is then added to a priority queue, where the priority of a buffer is it's depth in the tree. Next, the buffer flushing process is invoked. The buffer flushing process picks the buffer of lowest (nearest leaf level) depth in the tree from the priority queue and routes all queries from this buffer to the leaf level or possibly to another buffer. To route queries the first query is popped off the buffer and we route it, in depth first manner, to report all leaves, loading nodes from the R-Tree into main memory as necessary. If there is still available memory we can route the second query and so on until the main memory allocated for R-Tree nodes (1/2 of main memory) is exhausted. At this point we continue to route the current query (and others from the buffer being flushed) however if the search path at node v for some query q leads to a child of v that is not in main memory we fix a buffer to v, add q to the buffer and add the buffer to the priority queue. If there is already a buffer fixed to v we simply insert q into this buffer.
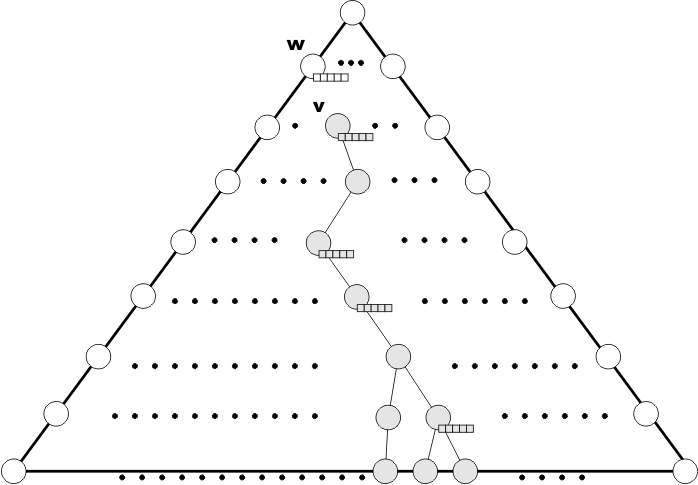
Figure 5 shows the floating buffer tree during the flushing stage. Below psuedo-code for the proceedure is listed along with explanatory notes.
|
Proceedure BulkQuery( list of queries Q ) 1. create new buffer at root node 2. insert all elements of Q into root buffer 3. insert root buffer into priority queue PQ with depth as priority 4. call FlushBuffers(PQ)
Proceedure FlushBuffers( buffer priority queue PQ )
1. while {PQ is not empty}
a. get lowest buffer from PQ
b. v <= node associated with lowest buffer
c. for {each query in buffer of v}
(i) for {each unvisited child of v}
- if {child is in memory or memory is not exhausted}
* load child into memory (if necessary)
* Route(child, query)
- else {memory is full}
* if {shadow buffer t does not exist}
fetch t from buffer pool1
* insert query into t
d. delete current buffer from v
e. if { t is not empty }
(i) fix t to node v
(ii) insert t into PQ
Proceedure Route( node v, query q )
1. if {v is a leaf}
a. report all results
2. else
3. a. for {each child of v}
(i) if {child is in memory or memory is not exhausted}
- Load child into memory if necessary
- Route(child, q)
(ii) else {memory is full}
- if {v has a buffer}
* insert query into buffer of v
- else {v has no buffer}
* create a new buffer and insert q2
* fix buffer to node v
* insert buffer into PQ
* break from for loop3